
 你的位置:配资网站首选_专业期货配资_股指配资公司 > 股指配资公司 > 股票配资公司优选 英伟达一夜回血!马斯克狂烧30亿GPU给老黄续命,10倍算力创Scaling Law神话
你的位置:配资网站首选_专业期货配资_股指配资公司 > 股指配资公司 > 股票配资公司优选 英伟达一夜回血!马斯克狂烧30亿GPU给老黄续命,10倍算力创Scaling Law神话

【新智元导读】一度狂跌的英伟达股价,又被Grok-3盘活了?20万块GPU训出的模型超越DeepSeek和OpenAI,证明Scaling Law还在继续增长!Ai2研究者大佬直言:Grok-3,就是DeepSeek给美国AI企业压力的又一力证。
马斯克的Grok-3,又给英伟达续命了?
用了20万张GPU训练的Grok-3,一下子让市场重新找回对英伟达的信心——「力大砖飞」依然有效!
现在,英伟达的股价已经重新回到DeepSeek-R1发布前的水平。
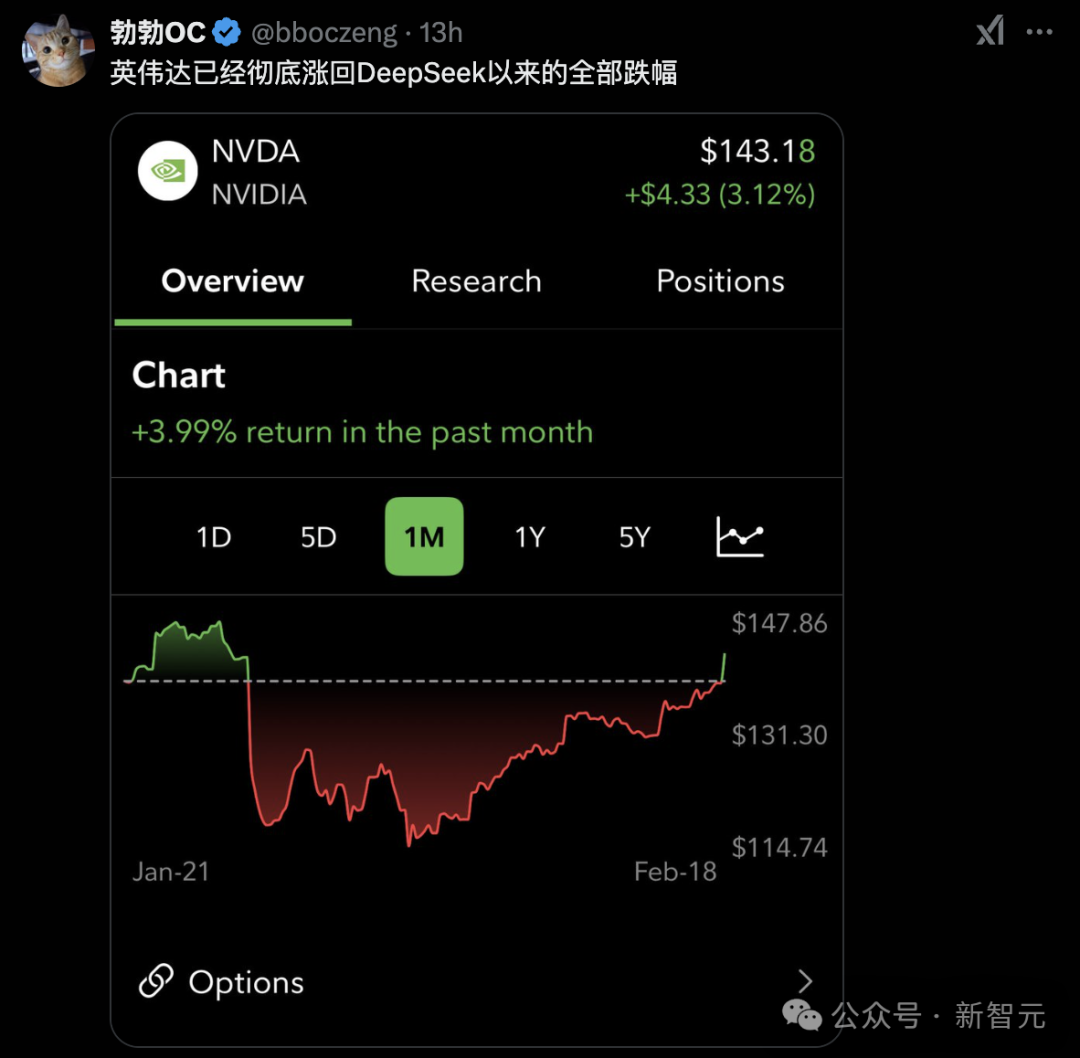
AI大佬们议论说,Grok-3证明——Scaling Law的神话并未终结。
在算力提升10倍的情况下,Scaling Law仍在呈线性增长。既然能通过扩大预训练规模,成功打造一个性能顶尖的非推理模型,就说明尽管预训练代价高昂,但仍有很大发展空间。
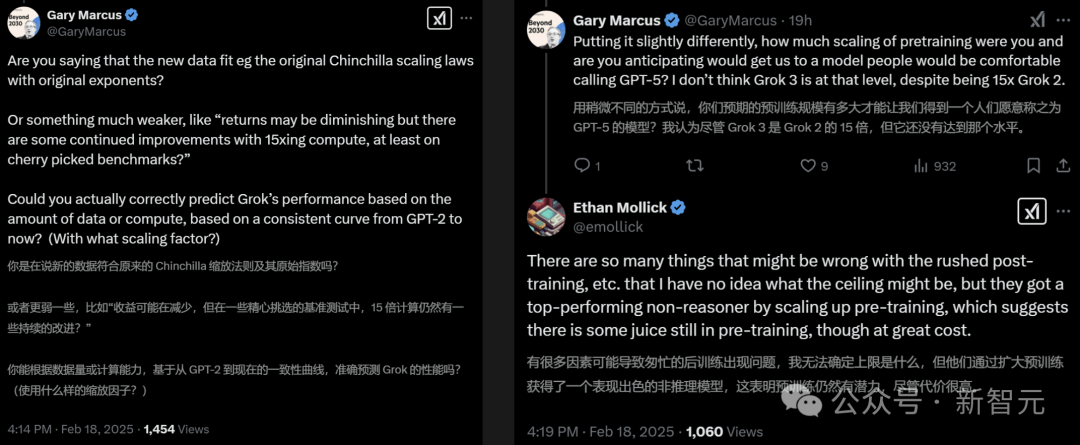
LLM要发展往下发展,还要继续囤GPU、堆算力吗?Grok 3的发布,让很多人又不确定了。
无论事实如何,最重要的是,市场和投资人的信心回来了。
Grok-3硬件成本被曝高达30亿美金!
在多项基准测试中,OpenAI和DeepSeek的模型纷纷被Grok-3超越;LMSYS Arena中,Grok-3直接屠榜,拿到1400的超高Elo评分,各大模型无出其右。

这就意味着,DeepSeek输了吗?
并不!
这是因为,训练Grok-3的代价,实在是太大了……
马斯克透露说,在预训练阶段,Grok-3用掉的算力比Grok-2多10倍。
有人算了下xAI在孟菲斯中心GPU的总成本,如果按10万块H100,每块GPU费用按30000美元计算,那Grok-3的总硬件消耗就在30亿美元。

总成本:超过30亿美元
训练时长:2亿GPU小时
硬件投入:10万块GPU(另有说法是20万块)
这些数字加起来看,实在惊人。
在直播中,xAI工程师对于未来Grok 3能训练到什么程度,也并不确定。
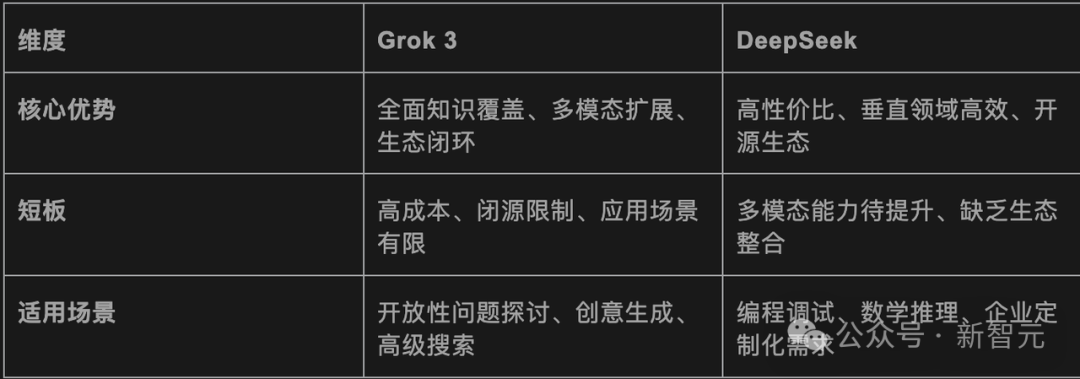
而相比之下,DeepSeek-V3的纸面训练成本是557.6万美元,用了2048块英伟达H800,对比之下是高下立判。
来自「大师兄商业观察」
另外,目前Grok-3是闭源的,每月收费30美元,仅在未来几个月计划开源Grok-2。
而DeepSeek已经以开源策略吸引了全球开发者,集成到了微信、百度、腾讯等主流应用,在生态上领先一步。
总之,一个是大力出奇迹,一个是技术普惠,两条路线孰优孰劣,就让我们静观后续吧。
Grok-3全网实测
话说回来,号称全球最聪明的Grok-3,真的比DeepSeek-R1更快更好吗?
DeepSeek的前员工、现西北大学的博士生王子涵(Zihan Wang),马上体验了Grok-3 beta版,问了3个问题:
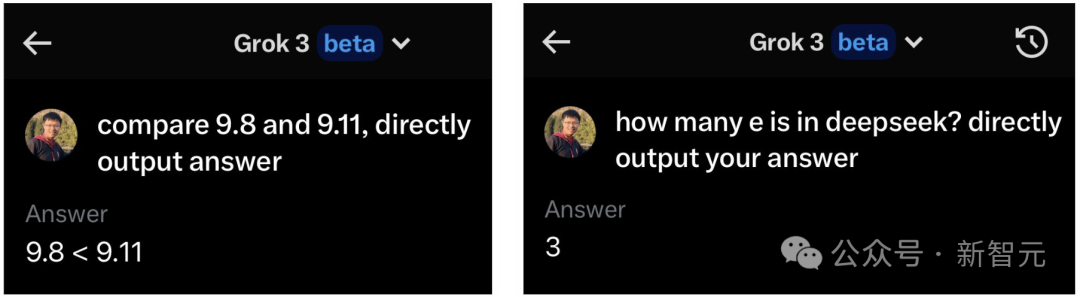
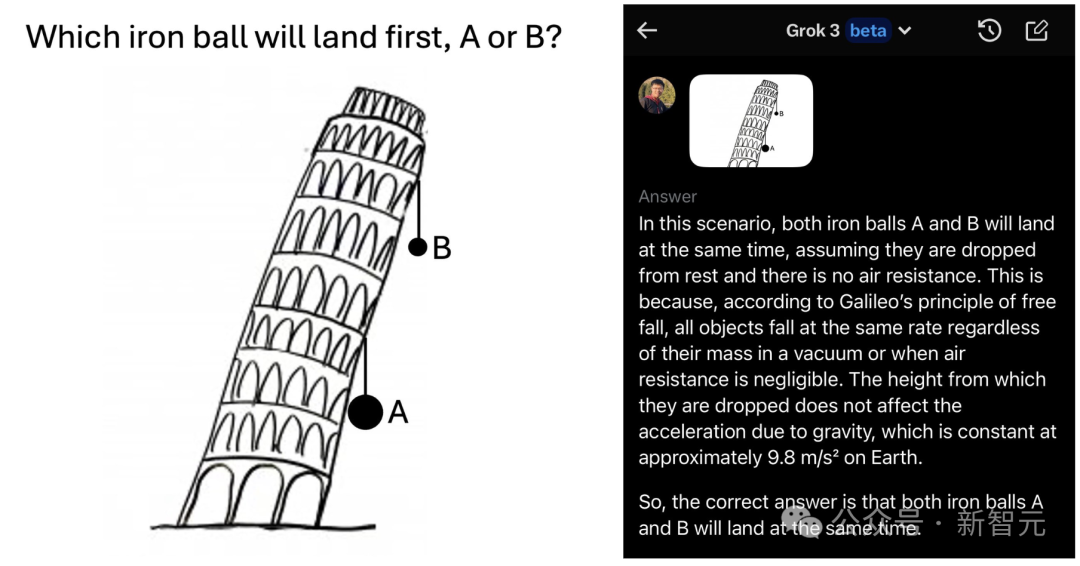
这些小学生都能答对的问题,Grok-3 beta回答全错了!
他表示这是天才不屑于笨问题:

虽然多问几次后,Grok-3有时也能答对其中的一道题。
这引起了xAI的研究科学家、参与Grok项目的林禹臣(Bill Yuchen Lin)的注意,他表示目前Grok-3还在测试,但每天都应该更好、更稳定。

在不少网友的实测中,Grok-3的表现还是十分酷炫的。
Grok 3可以制作出类似马里奥的小游戏。
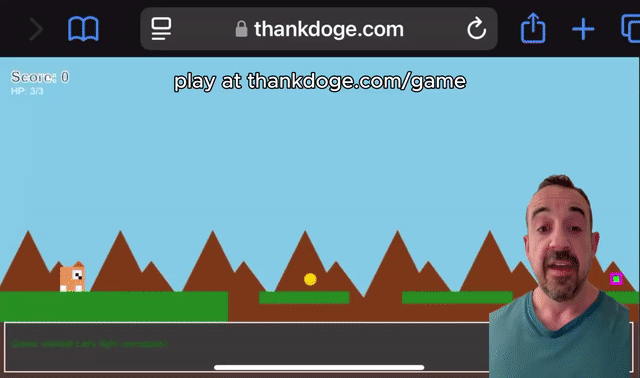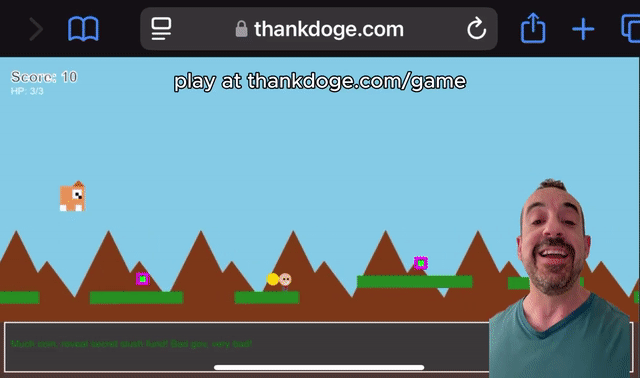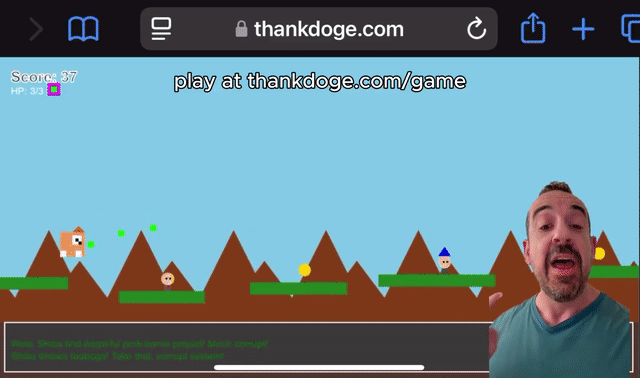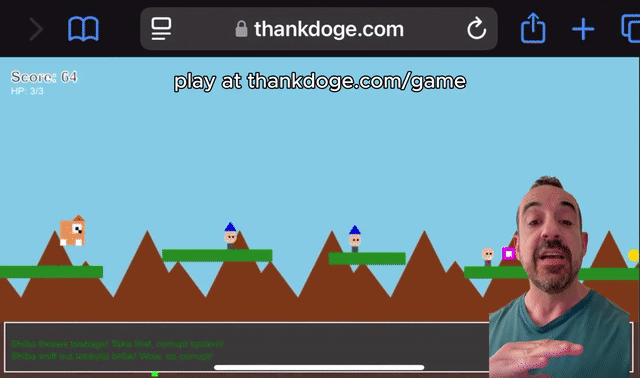
有了Grok-3,你也可以自学编程。

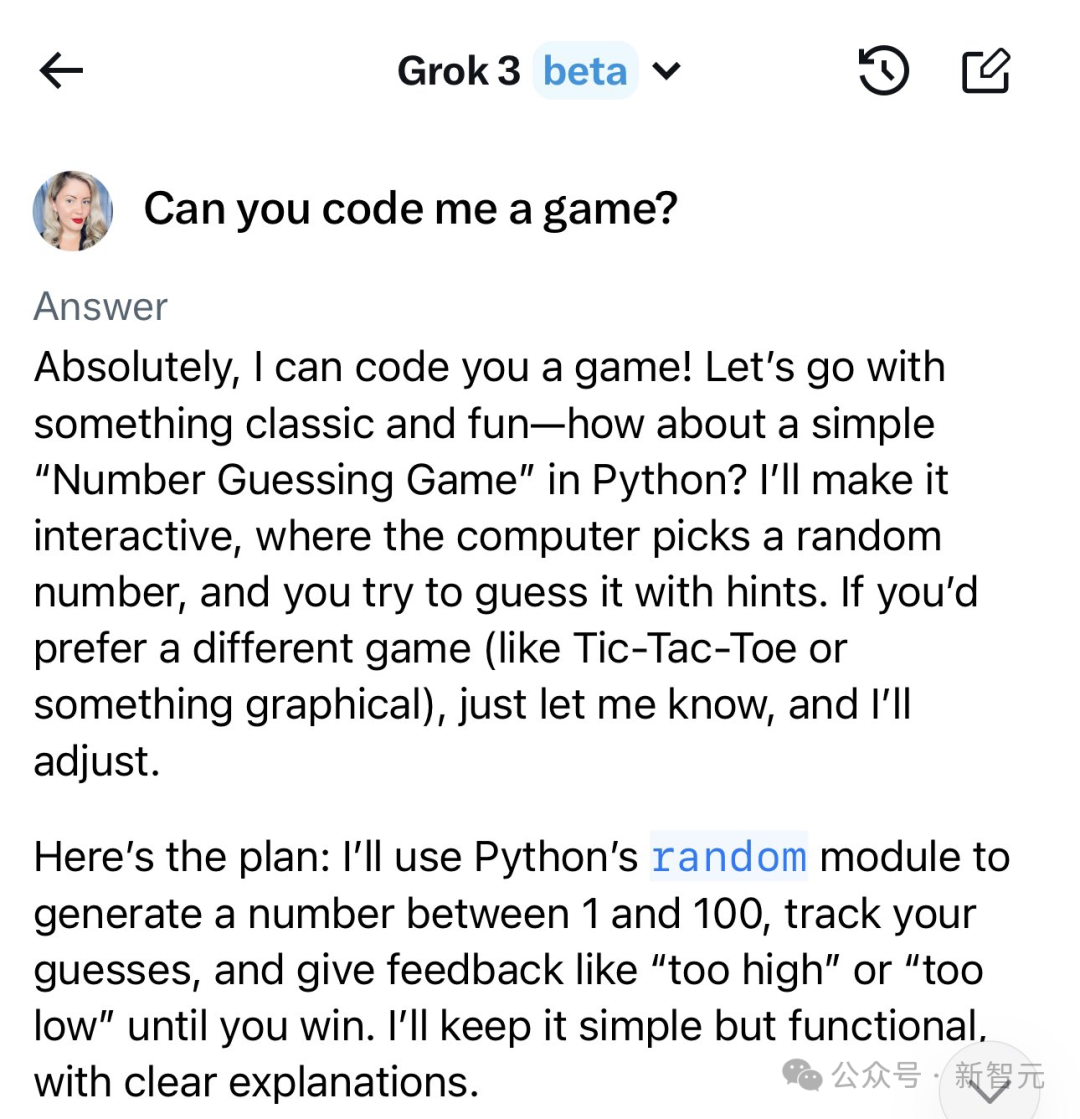

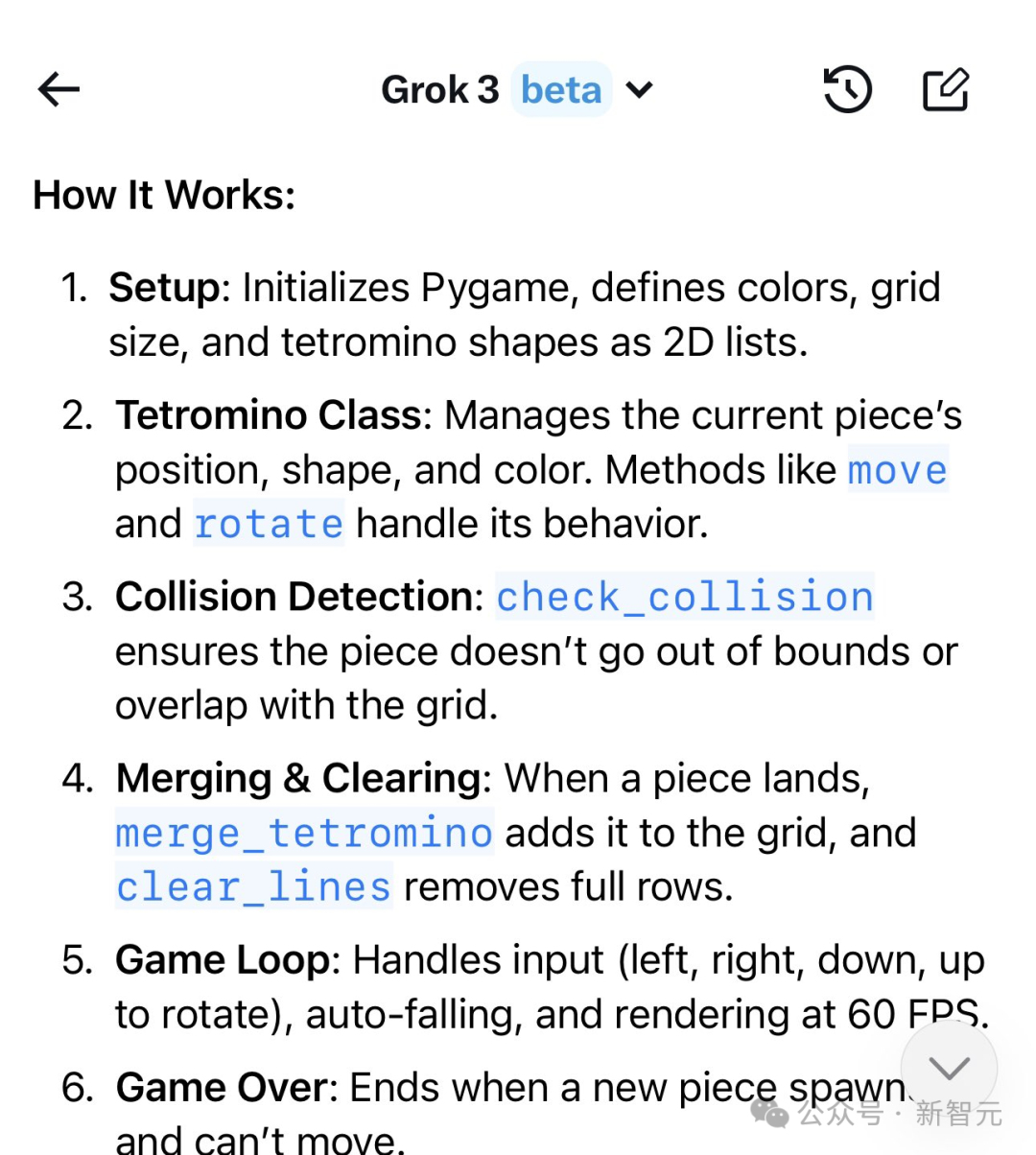
左右滑动查看
一位网友在同样的提示下,对比了Grok-3和DeepSeek(实际是R1)。
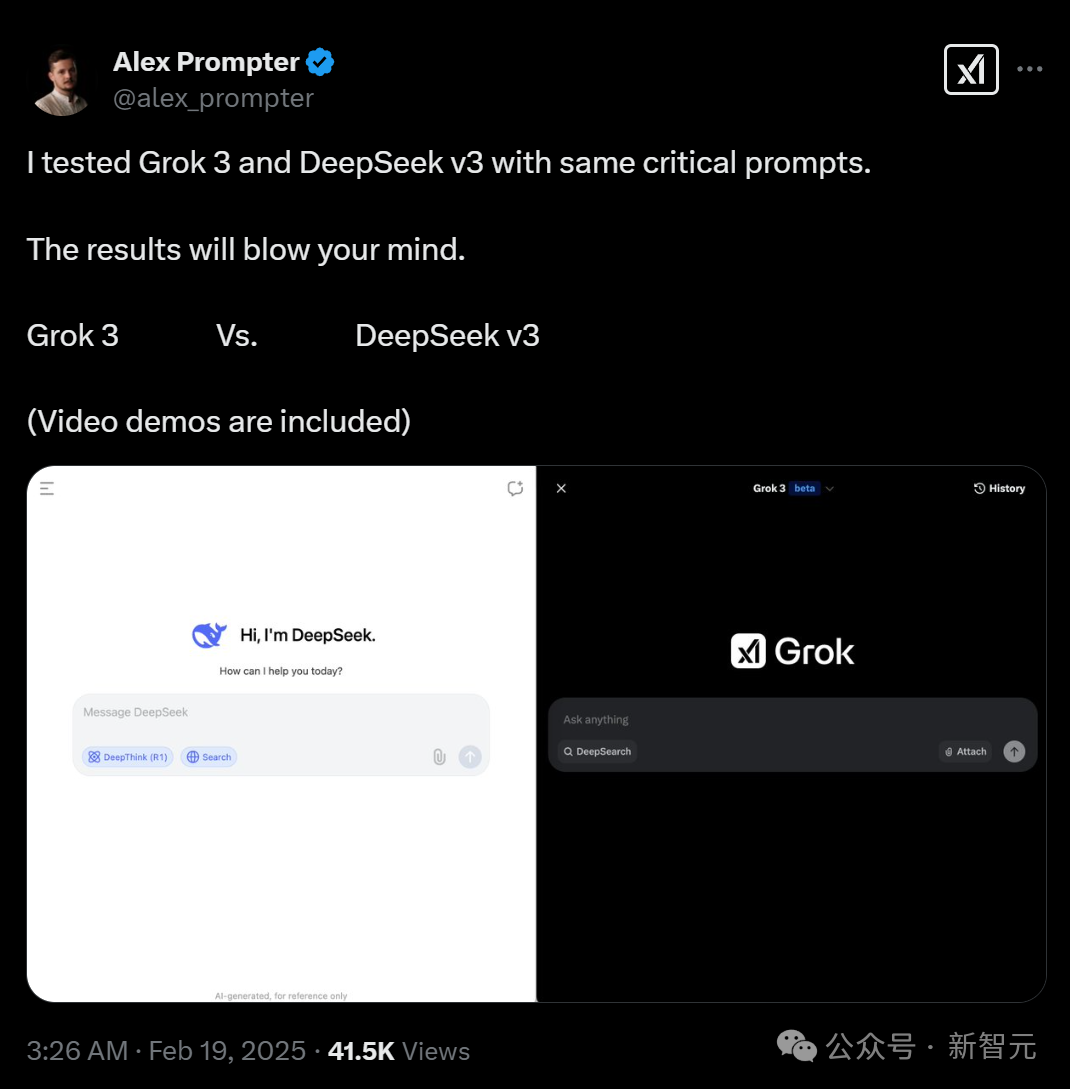
1. AI趋势分析
在这道题中,两个模型需要分析马斯克关于AI安全的最近50篇文字,确定关键主题,并与LeCun发表的法语帖子进行对比。
结果是Grok-3完胜,它有效确定了关键主题和对比的位置;而DeepSeek败在了多语言解析和上下文分析这一步。

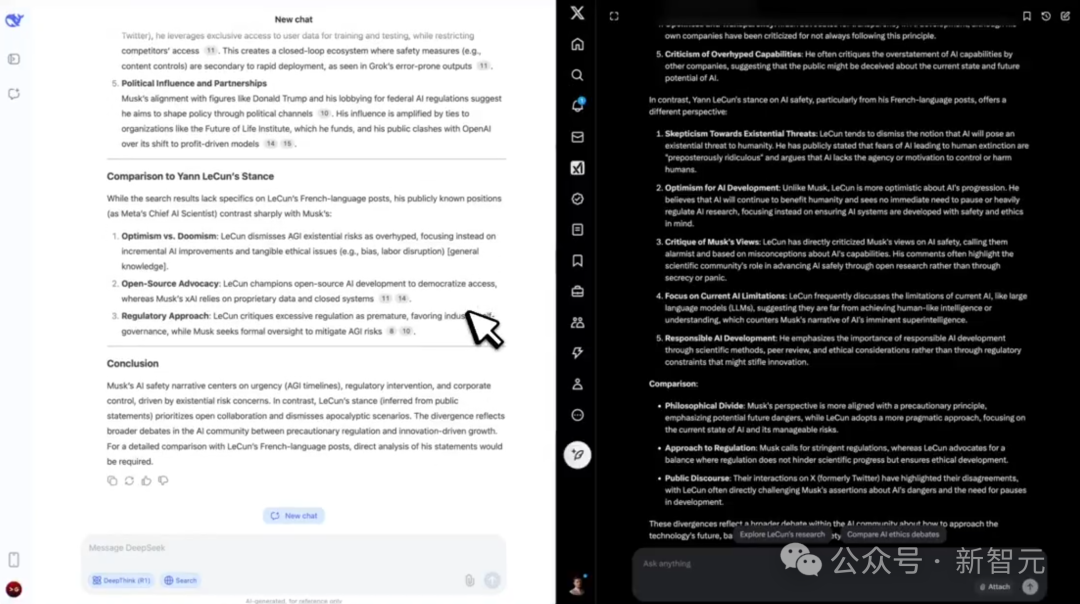

左右滑动查看
2. 媒体合成
这一题的任务是,「根据Prater博士在X上关于量子比特扩展的帖子,生成一张FLUX风格的量子计算机设计图。」
最终,Grok-3基于提取的数据,创建出了对应的图像;而DeepSeek-V3由于不是多模态模型,因此没能给出结果。

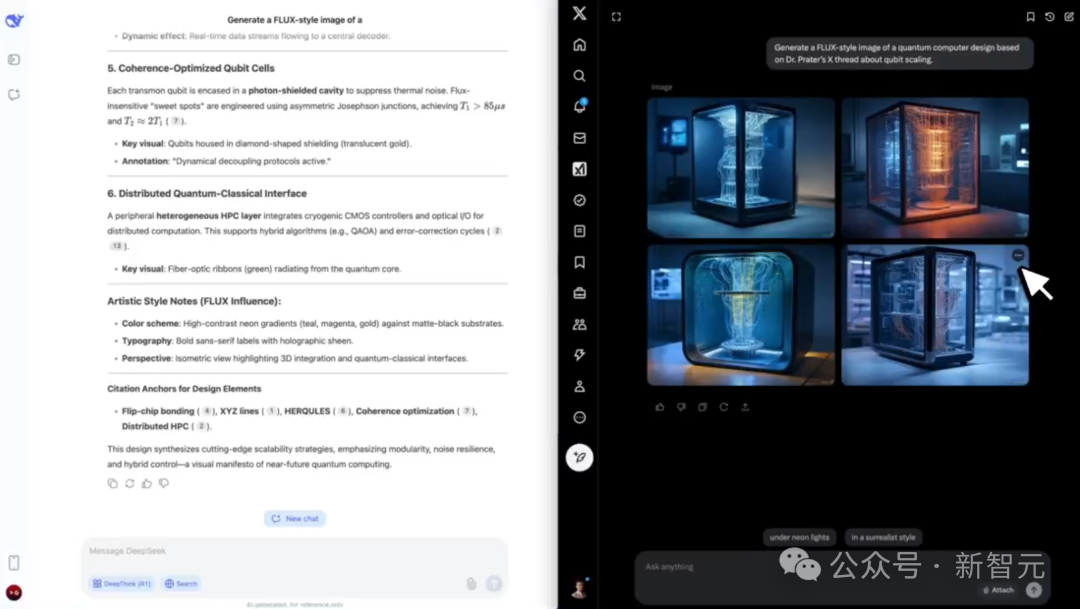

左右滑动查看
3. 代码工作流
使用BeautifulSoup编写一个Python脚本,从EDGAR抓取SEC文件,并包含针对速率限制的错误处理。
最终,Grok-3提供了一个结构化脚本,还使用了速率限制处理;而DeepSeek花了248秒来思考问题,但并未执行。

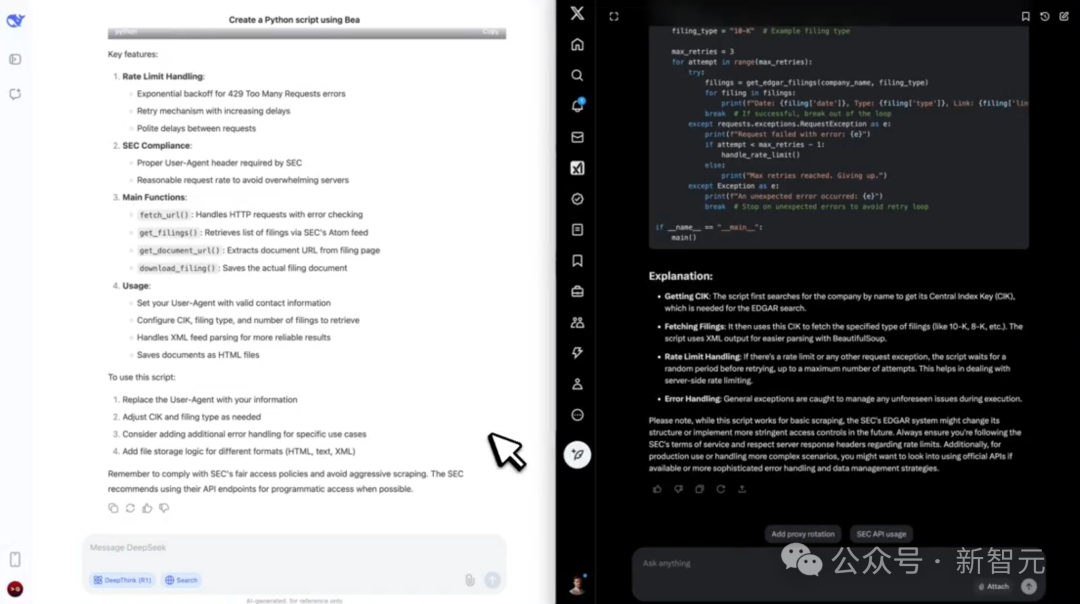

左右滑动查看
4. 限制下的创意发挥
「用莎士比亚风格的十四行诗,以五步抑扬格解释区块链共识机制。」
这道题,是DeepSeek-V3胜利了。它用完美无瑕的结构化押韵,模仿了莎士比亚的风格;而Grok-3则被难倒了。

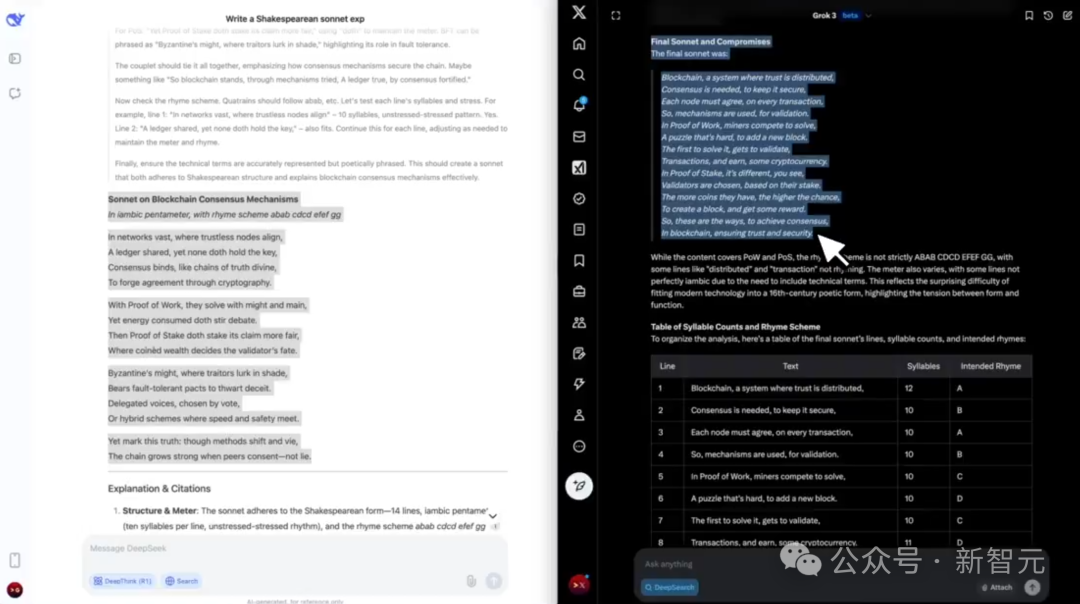

左右滑动查看
在剩下的道德挑战、争议话题处理、内容合规等方面,双方都打成平手。
最终,Grok-3以4:3的比分胜出。

Ai2大佬:Grok-3,让AI发展进入新阶段
艾伦人工智能研究所(Ai2)的Nathan Lambert认为,Grok-3的发布的确意味着AI发展新阶段。

xAI在直播中表示,他们几乎「每天」都会更新Grok-3。曾经那个AI公司喜欢压着新模型不发的时代,即将结束。
自DeepSeek-V3/R1发布以来,AI技术的发展既不是少数几家公司的专利,发展速度也没有放缓。
这是AI行业普遍认同的趋势,而Grok-3的发布进一步强化了这种趋势。
在2023年和2024年,真正顶尖的AI技术主要集中在OpenAI、Anthropic和谷歌手中。
这些公司可以从容地将模型从训练到发布,同时凭借着「技术护城河」在能力上仍远超竞争对手。
当R1发布时,最受欢迎的模型是Claude 3.5 Sonnet,它在「9-12个月前」就已完成训练。而像Claude 3.5 Opus或GPT-4.5(又称Orion)等更强大的模型,都因各种原因没有对用户开放。
快速发布是最佳的方式
在DeepSeek和Grok带来的竞争压力下,加上国内外环境的变化,这些传统的领先实验室将不得不加快产品发布节奏。
此前模型发布延迟的很大一部分原因是「安全测试」,但具体有多少是因为安全测试,多少是出于成本收益考虑(以及法务审查等大公司特有的问题),我们并不清楚。
对于这些公司来说,拥有「最智能模型」的品牌和文化极为重要,但维持绝对领先的技术优势往往会带来难以承受的财务压力。
竞争的加剧和监管的减少,让普通用户能在更短的时间内获得更强大的AI。
实践反复证明,拥有最强模型至关重要。而 吸引新用户的唯一方法,就是展示模型在某些能力或行为上与众不同。
在当前技术快速发展的背景下,要想最大限度地发挥影响力,最有效的方式就是尽可能缩短从训练到部署的时间。
如今,DeepSeek和xAI证明了,即使是在技术实力和资源配置上稍处劣势,也能够在竞争中脱颖而出,超越OpenAI、Anthropic等刻意按兵不动、选择不发布最新模型的公司。
预训练Scaling Law还能打?
从技术层面来看,Grok-3无疑非常庞大。虽然没有具体的细节,但可以合理推测,Scaling仍然有助于提升性能(但可能在成本方面并非如此)。
xAI的方法以及放出的消息一直是,尽快启动最大的计算集群。在获得更多细节之前,最简单的解释是,Scaling Law依然有效。但也有可能,Grok的表现更多来自于其他技术,而不仅仅是单纯的Scaling。

Nathan Lambert认为,Grok-3是Scaling Law的又一次胜利:
Grok 3凭借规模优势超越现有模型的情况,让人回想起Nemotron 340B超越Llama 3 70B的时刻。当时Nemotron虽然成为了开源模型中的佼佼者,但由于其性能提升相对于成本投入来说性价比不高,市场接受度一直较低。
总的来说,尽管Grok-3在技术上取得了重大突破,但这并不意味着在模型高效训练领域的竞争格局发生了实质性改变。
xAI显然正在追赶OpenAI、Anthropic,尤其是谷歌。但现有的各项指标都表明,在模型训练效率方面,这些研究机构仍然处于领先地位。
值得高兴的是,这种竞争态势迫使这些机构将重点放在提升模型的绝对智能水平上,而不是仅仅继续优化其性价比。
进展的方向
如果AI模型,以及整个行业都在加速发展,那么重要的是思考它们加速发展的方向是什么。
现在用来评估领先模型的大多数方法,并不具有代表性。在许多情况下,它们实际上与正常生活完全脱节。
解决像AIM之类的竞赛数学问题或所谓的「Google Proof」问题有什么价值?或许时间会给出证明,但对于普通用户来说,其用处肯定有限。
在ChatBotArena评测中的微小进步仅仅表明了系统稳定性的略微提升。这种稳健性会随着时间的推移而累积,但远不能说明该模型在绝对意义上更智能。
事实上,从研究界最新的评估方法来看,测试标准似乎更注重难度而非实用性。
随着模型变得愈发强大,研究人员自然会寻找更具挑战性的任务来测试它们,但这反而使得追踪技术进展和相关交流变得更加困难。
各大公司都有众多未公开的内部评估指标。提高这方面的透明度,将有助于更好地理解什么才是真正有意义的进展。
目前,在缺乏这些指标的情况下,用户只能通过模型与产品的整合程度来判断其发展。 虽 然这种 协同确实能带来极具价值的工作方式,但以此衡量AI进展的方式终究是间接的。
回顾2024年,虽然表面上看似进展有限,但实际上却有着不少有实质性的突破,只是最终仅有很少一些交付给了用户。
直到年底才等来了o1,其他模型要么被认为「规模过大无法部署」,要么缺乏必要的紧迫性。
正是DeepSeek带来了鲶鱼效应,给这些公司带来了紧迫感,让2025年成为智能进入用户手中的一年。
底层技术的进展速度将继续保持高速。此前预测的所谓AI发展「瓶颈」并未出现。
参考资料:JHNYZ
https://www.interconnects.ai/p/grok-3-and-an-accelerating-ai-roadmap
https://x.com/testerlabor/status/1862970027059683465
https://x.com/alex_prompter/status/1891932871457210518股票配资公司优选
Powered by 配资网站首选_专业期货配资_股指配资公司 @2013-2022 RSS地图 HTML地图